Partner POV | What is an AI Pipeline? Why does Storage Matter?
In this article
Article written and provided by Pure Storage.
An AI data pipeline is a data pipeline that feeds AI use cases. A standard data pipeline is a set of tools used to extract, transform, and load data from one or more sources into a target system of any type. In the case of an AI data pipeline, the pipeline consists of all the tools and data delivery methods that fuel the AI system.
Why Do AI Data Pipelines Matter Now?
Advances in deep neural networks have ignited a new wave of algorithms and tools for data scientists to tap into their data with AI. Thanks to improved algorithms, larger data sets, and open source machine learning frameworks, data scientists can tackle powerful new use cases, such as autonomous driving vehicles, natural language processing, and advanced medical research. But first, they need a way to easily collect, collate, process, store, and analyze the data that feeds AI models.
For example, as explained on a recent AI Today Podcast, one of the reasons products like Pure Storage's FlashBlade was invented was to help companies handle the rapidly increasing amount of unstructured data coming their way thanks to the training of AI models.
Listen to Justin Emerson talk about the relationship between AI and data storage on the AI Today podcast
Data is 100% at the heart of modern deep learning algorithms. Before training can even begin, the hard problem is collecting the labeled data that is crucial for training an accurate AI model. Then, a full-scale AI deployment must continuously collect, clean, transform, label, and store larger amounts of data. Adding additional high-quality data points directly translates to more accurate models and better insights.
A major part of maintaining good quality data happens in the AI data pipeline lifecycle, which companies use to generate quality insights and accelerate outcomes from the efforts of data scientists.
The AI Data Pipeline Lifecycle
In AI data pipelines, data packets undergo a series of processing steps, including:
- Ingestion, where the data, typically in the form of a file or object, is ingested from an external source into the AI model training system.
- Cleaning, where the raw data is sorted, evaluated, and prepared for transfer and storage.
- Exploration, where some of the data is used to test parameters and models, and the most promising models are iterated on quickly to push into the production cluster.
- Training, where phases select random batches of input data, including both new and older samples, and feed those into production GPU servers for computation to update model parameters. Finally, a portion of the data is held back to evaluate model accuracy.
- Deployment, the model put into production, operating on a stream of data to achieve its design goals. For example, make shopping recommendations, recognize images in a video stream, etc.
This lifecycle applies to any type of parallelized machine learning, not just neural networks or deep learning. For example, standard machine learning frameworks, such as Spark MLlib, rely on CPUs instead of GPUs, but the data ingest and training workflows are the same.
The Importance of Data Storage for AI Pipelines
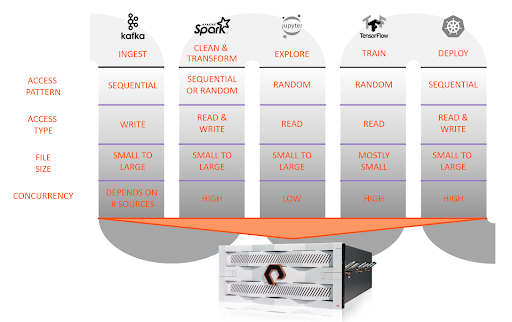
As seen above, each stage in the AI data pipeline has varying requirements from the underlying storage architecture. To innovate and improve AI algorithms, storage must deliver uncompromised performance for all manner of access patterns, from small to large files, from random to sequential access patterns, from low to high concurrency, while still providing the ability to easily scale linearly and non-disruptively to grow capacity and performance.
For legacy storage systems, this is an impossible design point to meet, forcing the data architects to introduce complexity that slows down the pace of development.
In the first stage, data is ideally ingested and stored on the same data platform such that the following stages do not require excess data copying. The next two steps can be done on a standard compute server that optionally includes a GPU, and then in the fourth and last stage, full training production jobs are run on powerful GPU-accelerated servers like the NVIDIA DGX systems. Often, there's a production pipeline alongside an experimental pipeline operating on the same data set. Further, the DGX GPUs can be used independently for different models or joined together to train on one larger model, even spanning multiple DGX systems for distributed training.
A single shared storage platform creates a coordination point throughout the lifecycle without the need for extra data copies among the ingest, pre-processing, and training stages. Rarely is the ingested data used for only one purpose, and shared high-performance storage gives the flexibility to interpret the data in different ways, train multiple models, or apply traditional analytics to the data.
If the shared storage tier is slow, then data must be copied to local storage for each phase, resulting in wasted time staging data onto different servers.
The ideal data storage platform for the AI training pipeline delivers similar performance as if data was stored in system RAM while also having the simplicity and performance for all pipeline stages to operate concurrently.
Why Pure Storage for AI Data Pipelines
Pure Storage® FlashBlade//S® is the ideal data platform for AI, as it was purpose-built from the ground up for modern, unstructured workloads and supports the entire AI data pipeline.
A centralized data storage platform in a deep learning architecture increases the productivity of data scientists and makes scaling and operations simpler and more agile for the data architect.
FlashBlade//S specifically makes building, operating, and growing an AI system easier for the following reasons:
- Performance: With up to 60GB/s of read bandwidth per chassis, FlashBlade//S can support the concurrent requirements of an end-to-end AI workflow.
- Small-file handling: The ability to randomly read and write small files with FlashBlade//S means that no extra effort is required to aggregate individual data points to make larger, storage-friendly files.
- Scalability: FlashBlade//S disaggregated architecture allows you to start off with a small system and then add blades to increase capacity or performance as either the data set grows or the throughput requirements grow.
- Native object support (S3): Input data can be stored as either files or objects.
- Simple administration: There's no need to tune performance for large or small files and no need to provision file systems.
- Non-disruptive upgrade (NDU) everything: Protect your storage investments with a platform where software upgrades and hardware expansion or update can happen anytime, even during production model training.
- Ease of management: Pure1®, our cloud-based management and support platform, allows users to monitor storage from any device and provides predictive support to identify and fix issues before they become impactful. With Pure1, users can focus on understanding data and not on administering storage.
- Future-proof: FlashBlade//S is built with a flexible, Evergreen architecture that remains current for a decade or longer. It's modular components can scale independently, flexibly, and be upgraded non-disruptively based on changing business requirements.
Small-file handling is especially critical as many types of inputs, including text, audio, or images will be natively stored as small files. If the storage tier does not handle small files well, an extra step will be required to pre-process and group samples into larger files. Most legacy scale-out storage systems are not built for small file performance.
Also, storage built on top of spinning disks that rely on SSD as a caching tier falls short of the performance needed. Because training with random input batches results in more accurate models, the entire data set must be accessible with performance. SSD caches only provide high performance for a small subset of the data and will be ineffective at hiding the latency of spinning drives.
Ultimately, the performance and concurrency of FlashBlade//S means that data scientists can quickly transition between phases of work without wasting time copying data. FlashBlade//S also enables executing multiple different experiments on the same data simultaneously.