Using PFC and ECN queuing methods to create lossless fabrics for AI/ML
In this article
Introduction
Widely available GPU-accelerated servers, advancements in hardware, and popular programming languages like Python and C/C++ have made it easier to develop GPU-accelerated ML applications. Frameworks such as PyTorch, TensorFlow, and JAX further simplify the development process. These applications are used in various domains, including medical research and self-driving vehicles, and rely on large datasets and GPU clusters for training deep neural networks. Inference frameworks apply the knowledge from trained models to new data, leveraging optimized clusters for improved performance.
AI workloads often involve long learning cycles that can span days or weeks. In such scenarios, high-latency and lossy communication between GPU server clusters can significantly impact job completion times or lead to failure. AI workloads require low-latency, lossless networks, necessitating appropriate hardware, software features, and configurations to address this. RoCEv2-based Ethernet solutions for connecting GPUs require advanced queueing techniques to provide the needed lossless fabric by GPU accelerators.
The need for multiple GPU and Parallelism
To better understand why the standard ethernet-based fabric cannot support Inter-GPU communications, we must understand how and why GPUs must communicate with each other. During the initial AI/ML training stage, raw data is collected from various sources, including the Internet, databases, and cloud storage. Data scientists then label or segment the data into tokens. These tokens will train the neural network system to generate accurate query responses. Training such extensive datasets requires substantial computational power, often involving numerous GPUs managing data exceeding petabytes. The data and tokens are divided into smaller batches and processed on multiple GPU nodes using parallel computing techniques like data and model parallelism.
Embracing RoCE for efficiency, the AI backend leverages GPU clusters for intricate calculations, accelerating AI model training. Transferring the model's gradients between GPUs is crucial to maintaining output consistency as tasks shift. When AI/ML neural networks and data sets get large, the batch process jobs must be spread across multiple parallel GPUs in a node or between GPU nodes across a fabric using Parallelism techniques. GPU coherence protocols do not obtain ownership for written data or atomics, and they must perform synchronization between all GPU nodes in a cluster during the batch job runs. The batch job will do a local Sync and then a global send to synchronize non-local GPUs, as shown in the diagram below.
The GPUs in a cluster work together, performing calculations to achieve the desired outcomes. Synchronization occurs at the end of each batch run, ensuring all GPU nodes are in sync before starting the next batch run. This synchronization traffic is sent across all of the GPUs in the cluster, ensured through the RMDA protocol using RoCEv2 with Ethernet, referred to as "Long-Lived" or "Elephant flows." Below, we see how the batch jobs are run on a single GPU; a local sync is done and then sent outbound to connect to all the other GPUs in the GPU cluster design. Those GPUs then send their synchronization via their global send, and each GPU receives all of the Global sends from other GPUs. These are then used as a weighted average with the local sync, which finally does a Local update, and the subsequent batch job proceeds.
GPU synchronization problems
Let's examine the synchronization traffic patterns between GPU nodes running our neural networks. We see multiple cases where a single GPU has to send synchronization data to all of the other GPUs in a cluster. If the participating GPUs are not on the same GPU node, we MUST connect to the other GPUs across a fabric, in this case, an Ethernet-based RoCEv2 fabric. Since a high-end GPU can push 400Gbps of long-lived flows, it is pretty easy to see how a switch's input and output buffers can be overrun and start to drop packets. Since RoCEv2 is UDP-based, TCP retransmission techniques do not work, so these long-lived flows must be allowed to traverse the fabric from sender to receiver intact. As we can see in the All-Gather, All-to-All, and All-Reduce synchronization flow traverses the fabric in both directions, the fabric must support non-blocking and hence no packet loss for each flow in every direction.
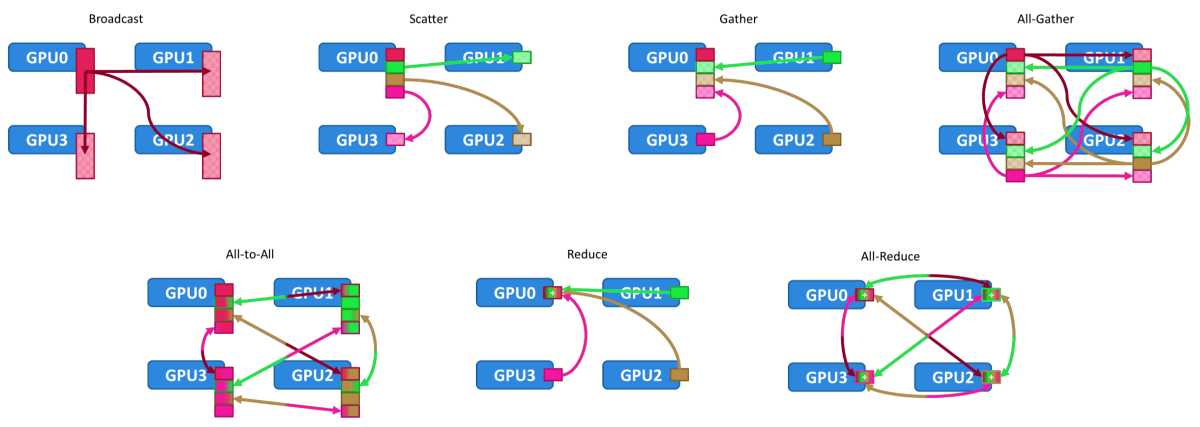
The congestion problem
Network congestion occurs when the volume of incoming data exceeds the outgoing link's bandwidth capacity in network switches. This often happens when multiple sources, such as GPUs, simultaneously send data to the same destination. While switch buffers can manage temporary congestion, prolonged congestion leads to buffers reaching their maximum capacity. Once the buffers fill, the buffers begin dropping new incoming packets, which hampers application performance due to the need for retransmission and the complexity of the transport protocol. To combat this, lossless networks use flow control mechanisms that halt incoming traffic before buffers overflow, thus avoiding packet loss. Nevertheless, flow control can also lead to the spread of congestion within the network.
Two networking buffering techniques called Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) can be used with careful tuning of buffer queue depth to provide a lossless fabric for GPU connectivity. An in-depth look into these protocols is needed to properly design, manage, and tune the fabric to provide lossless connectivity between GPU nodes.
RoCEv2 (RMDA over Converged Ethernet v2) as Transport for AI Clusters
Remote Direct Memory Access (RDMA) was first used on the InfiniBand network. It is direct access from one computer's memory to another without involving one's operating system or CPU processing. This implements high throughput, low latency, and high energy efficiency on the network.RDMA can also be applied to Ethernet networks using the network protocol RDMA over Converged Ethernet (RoCEv2).

RoCEv2 uses Remote Direct Memory Access (RDMA), a prevalent high-performance computing and storage networking technology. It is renowned for delivering high-speed and low-latency communication directly between computing nodes' memory. RDMA enhances efficiency by transferring the workload from the CPU to the network adapter hardware, circumventing the need for the operating system's network stack and leading to lower power consumption.
There are two RoCE versions: RoCEv1 and RoCEv2.
- RoCEv1 is a link layer protocol that allows communication between any two hosts in the same layer two broadcast domain.
- RoCEv2 is a network layer protocol that implements the routing of RoCEv2 packets to allow hosts in different broadcast domains to communicate. It is encapsulated based on the UDP protocol.
RoCEv2 provides three advantages:
- Operation on routed networks ubiquitous in large data centers
- IP QoS – The DiffServ code point (DSCP), or VLAN PRI
- IP congestion – The explicit congestion notification (ECN) signal
Figure 4 shows the format of a RoCEv2 packet.

- Ethernet Header: contains the source and destination MAC addresses.
- IP Header: contains the source and destination IP addresses.
- UDP Header: contains the source and destination port number. The destination port number is 4791.
- The InfiniBand Base Transport Header contains the main fields for intelligent traffic analysis. For details, see
- InfiniBand Payload: indicates the payload of a message.
- ICRC and FCS are used for redundancy checks and frame checks.
While the delivery sequence of RoCEv2 UDP packets may be unpredictable, the RoCEv2 standard mandates that packets sharing an identical UDP source port and destination address must be delivered in the original order without reordering. The UDP layer serves solely as a means to identify connections. It is characterized by a UDP/IP quintuple—destination address (da), source address (sa), protocol, destination port (dport), and source port (sport)—which facilitates network management tasks by existing systems, such as load balancing via ECMP and network monitoring tools.
The key differences between TCP and RoCE are:
- TCP is stream-based, while RoCE is message-based, and UDP
- TCP implementations are typically software-based, while RoCE is implemented in the hardware
- TCP controls an inflight window, the number of unacknowledged bytes, while RoCE controls the transmission rate
To accommodate RoCEv2 transport, a network fabric must deliver non-blocking, zero-packet-loss throughput and zero and minimal latency while mitigating congestion-related traffic loss. AI/ML optimized fabrics are equipped with advanced features that help preserve a lossless network ecosystem, thanks to their comprehensive software and hardware telemetry capabilities for Explicit Congestion Notification (ECN) and Priority Flow Control (PFC).
RoCEv2 also outlines the structure of Congestion Notification Packets (CNP. When ECN Congestion Experienced (CE) markings are detected, RNICs (RMDA capable NICs) dispatch CNPs to the sender to signal the need for a reduced transmission rate.
EXPLICIT CONGESTION NOTIFICATION (ECN)
Explicit Congestion Notification (ECN) was initially established for TCP/IP networks in RFC 3168. It introduced a system for signaling congestion through the IP header and confirming it via the TCP header. Devices such as switches and routers that support ECN can identify and flag packets to indicate network congestion. Additionally, the congestion signals in the IP header are utilized by RoCEv2's congestion control mechanisms.
BASIC ECN TERMINOLOGY
NP-Notification Point - the end node that receives the packets from the injector and sends back notifications to the injector for indications regarding the congestion situation.
CP-Congestion Point - the switch queue in which congestion happens
RP (Injector)-Reaction Point - the end node that performs rate limitation to prevent congestion
CNP- The RoCEv2 Congestion Notification Packet - The notification message an NP sends to the RP when it receives CE-marked packets.
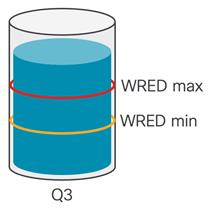
ECN Threshold—configured packet buffer queue in each switch. Once past the ECN Mark Threshold (in this case, WRED max), the switch will rewrite the ECT header to 0x1. In the figure below, we can see the max and min queue depth. We always want to keep the input and output queues below the max configured.
CONGESTION CONTROL LOOP
The RoCEv2 ECN congestion control loop is described in the stages below. Please refer to the diagram and the steps to understand how ECN controls congestion.
The injecting end station (Injector) or Reaction Point (RP) must set the ECN bits in the RoCEv2 IP header. The values of the bits are as follows: according to the RFC 3168 (ECT: ECN-Capable Transport), the injecting NIC sets the ECN field in the IP header to the value of ECT (01) (Note: Setting ECT (0) or ECT (1) is interchangeable.
- The RoCEv2 packet goes from the injector (Reaction Point) to the TOR switch with ECN=0x10. (Steps 1-2)
- The packet then goes through the spine without congestion, and the ECT header(ECN=0x10) remains unchanged (Step 3).
- The destination TOR leaf has a congested ingress queue (WRED over max); instead of dropping the packet, it will modify the ECN-capable field and turn ON the CE bit inside the IP header (0x03). (Step 4)
- The packet arrives from the network and goes to the receiver (Notification Point, in this case, a NIC). In the case of congestion, the ECN in the IP header is set to 0x03. We can see in the packet capture that the DSCP field is 0x03 CE (Congestion Experienced). (Step 5)
- The receiving end station filters the packets with the CE bit turned on and the traffic type (RoCE) ON, triggers the event and releases the packet to the normal processing flow. The receiving end station RNIC will aggregate Congestion Notifications for each injector (QP) to avoid load due to traffic generation.
- One Congestion Notification Packet (CNP) is returned to the injector via the fabric once every x microseconds (the timing depends significantly on the OEM switches' operation). The receiving end station sends a CNP packet back to the injector. (Step 6)
- The switches treat the RoCEv2 CNP as a regular IP packet. (Step 7)
- The CNP packet arrives at the injecting end station. The injecting end station RNIC applies the corresponding rate limiter to that flow, slowing it down. (Step 8)
When only a portion of data packets are tagged with congestion notification bits, the injecting end station decreases the flow's traffic rate but keeps sending packets. Should congestion persist and buffer usage exceeds the WRED's upper limit, the switch will label all packets as experiencing congestion. Consequently, the sender gets numerous congestion notification packets, prompting a significant reduction in data transmission rate per its algorithm. This action helps alleviate congestion, allowing the buffer to clear. The traffic rate can increase again until further congestion signals are detected. It's important to note that RNICs must be used to provide end-to-end ECN and CNP capability. The switch queue depths and the RNIC queues must be manually configured and monitored during training runs to properly configure the queues and give a lossless fabric.
802.3x Flow Control (Global Pause)
802.3x Flow Control, also known as Global Pause, is a mechanism in the Ethernet protocol that helps manage data flow to prevent buffer overflow. Initially, Ethernet didn't guarantee packet delivery, leaving that to higher-level protocols like TCP. However, the 802.3x standard was introduced to provide a solution for applications needing reliable data transfer at the Ethernet level. 802.3x specifies a receiving device will send a pause frame to the sender if its buffer is close to overflowing, halting data transmission until it's ready to resume. However, this system has a downside, as it can't differentiate between traffic types. So, when flow control is active, all traffic is paused, regardless of priority, which can lead to bottlenecks, especially in networks with diverse data flow requirements.
Priority Flow Control (PFC)
Priority Flow Control (PFC) emerged in Layer 2 networks to ensure Ethernet without data loss, utilizing the class of service (COS) value within Layer 2 frames to manage congestion through pause frames. Yet, the complexity of scaling Layer 2 networks led to a shift towards Layer 3 routed designs. With the advent of routable RoCEv2, PFC adapted to use layer 3 differentiated services code points (DSCP) for congestion notification across network hops. DSCP, which classifies layer 3 traffic on IP networks using a 6-bit field in the IP header, allows for consistent traffic classification through routers. PFC, essential for managing RoCEv2 congestion, operates per-hop, signaling from congestion points back to the traffic source, although this process may introduce delays in congestion notification.
Configuring Priority Flow Control (PFC) allocates a distinct service class queue for traffic that requires lossless transmission (such as RoCEv2), ensuring it is processed uniquely compared to other traffic types. Ports enabled with PFC receive an exclusive no-drop priority queue and buffer space, safeguarding the integrity of the data flow. The system's lossless mechanism is characterized by dual threshold levels within the queue. The upper threshold, the xOFF threshold, is critical for initiating a PFC frame that signals congestion when the buffer content reaches this level, prompting the frame to be dispatched to the originating traffic source. Conversely, as the buffer content decreases and dips below the lower xON threshold, the system halts the emission of pause frames, reflecting its determination that network congestion has been alleviated. This dynamic process ensures efficient network traffic management and maintains the quality of service for high-priority data streams.
The system employs a dual-threshold queue to ensure uninterrupted data flow. When buffer usage peaks, the higher xOFF threshold triggers the dispatch of a PFC frame to the traffic origin. Conversely, when the buffer depletes to the lower xON threshold, it ceases sending pause frames, indicating congestion resolution.
- Leaf 5, receiving GPU synchronization data from hosts 1 and 5, experiences port congestion en route to host 9. The switch's specialized buffer temporarily stores the traffic. Upon hitting the xOFF limit, Leaf 5 issues a pause frame to the next upstream hop network layer, represented by spine switch Spine-1.
- Upon receiving a pause frame, the spine switch Spine-1 ceases traffic transmission to Leaf-5 to alleviate potential congestion on Leaf-5 (while transmitting to other leafs that see no congestion). Concurrently, Spine-1 initiates traffic buffering within its no-drop queue. Once the buffer attains the xOFF threshold, Spine-1 dispatches pause frames to the downstream devices, Leaf-1 and Leaf-3, actively routing traffic to the spine switch. This mechanism ensures a controlled flow of data and prevents network overload.
- As the pause behavior propagates hop by hop, the leaf switches connecting the senders begin to receive pause frames. Consequently, these switches halt their transmission to the spine switch and initiate traffic buffering. This chain reaction results in Leaf-1 and Leaf-3 sending pause frames towards Host 1 and Host 5, respectively.
- When the senders (GPU nodes) get a pause frame, the data flow decreases in speed, enabling the network switches' buffers to clear. Once a receiving device hits the xON threshold, it ceases to send out further pause frames. As the network congestion eases and the transmission of pause frames stops, Host 9 resumes its regular traffic reception.
This pausing process is initiated at the point of congestion. It propagates back to the origin of the data whenever the network experiences congestion or when Priority Flow Control (PFC) is active at a terminal point. This mechanism, illustrated in the given example, mandates that every device receive a pause frame along the route before transmission ceases, thereby averting packet loss.
Occasionally, a phenomenon known as a PFC storm may arise if a host persistently sends out PFC frames, leading to an overload of the network nodes' buffers. This can escalate until it halts the entire network once it extends to all terminal hosts. Implementing the PFC watchdog function is recommended to mitigate such disruptions.
- A PFC storm can be triggered upon NIC or link malfunction to send continuous PFC frames into the network. In the example below, host nine has NIC problems and sends out continuous PFC frames.
- The network will propagate those frames to all senders.
- The PFC storm will stop all traffic coming from the sender
- PFC watchdog can drain the queues.
Understanding PFC Watchdog
In lossless Ethernet, Priority-based Flow Control (PFC) pause frames halt packet transmission from the connected device. These frames can spread network-wide, potentially stopping traffic in PFC streams. The PFC watchdog is designed to identify and address such PFC pause storms.
This PFC watchdog monitors ports for signs of pause storms. The watchdog intervenes if a port continuously receives PFC pause frames without corresponding flow control frames. It temporarily turns off the impacted queue for a set recovery period. Once this period is over, the queue is reactivated.
The PFC watchdog has three functions: detection, mitigation, and restoration.
Detection- The PFC watchdog checks the status of PFC queues at regular polling intervals. If the PFC watchdog finds a PFC queue with a non-zero pause timer, it compares its current transmit counter register to the last recorded value. If the PFC queue has not transmitted any packets since the previous polling interval, the PFC watchdog checks if there are any packets in the queue. If packets on the queue are not being transmitted and there are no flow control frames on that port, the PFC watchdog detects a stall condition.
Mitigation-After the PFC watchdog detects a stall condition, it turns off the queue where it detected the PFC pause storm for a set recovery time. During that time, it flushes all packets in the queue and prevents new packets from being added. The system monitors all packet drops on the PFC queue during the recovery time.
Restoration-When recovery ends, the PFC watchdog collects the ingress drop counters and any other drop counters associated with turning off the PFC queue. It maintains a count of the packets lost during the last recovery and the total number of lost packets due to PFC mitigation since the device was started. The watchdog then restores the queue and re-enables PFC.
Can PFC and ECN be used at the same time?
In the specialized data center setting, mainly where RoCEv2 Ethernet fabrics are employed for training AI models, ECN and PFC are crucial for congestion management. ECN offers long-term congestion feedback, facilitating the adaptive regulation of data transmission rates. Conversely, PFC swiftly reacts to congestion by halting specific traffic flows, instantly averting packet loss.
ECN contributes to the network's overall efficiency by modulating traffic flow in response to congestion signals. Meanwhile, PFC acts as a safeguard to prevent the loss of crucial, time-sensitive data during temporary congestion. When ECN is paired with PFC, the Ethernet network is equipped to handle traffic more efficiently, avoiding packet loss and ensuring a high data transfer rate. This is crucial for completing AI model training tasks on time.
Data Center Quantized Congestion Notification (DCQCN) merges the capabilities of ECN (Explicit Congestion Notification) and PFC (Priority Flow Control) to enable a fully lossless Ethernet experience. By utilizing ECN's network's ability to manage congestion through reduced transmission rates, DCQCN effectively limits the need for PFC, which halts data flow during congestion events. This synergy ensures smoother traffic flow and enhances overall network efficiency.
Next steps
In the following article, we shall examine DCQCN and how it combines the features of PFC and ECN to provide a lossless ethernet fabric for AI workloads. In the following article, we shall also dive into TOR switch design for inter-connecting GPUs for lowering latency and thereby lowering Job Completion Times (JCTs)